

Data availability - Key to Trustless Blockchains
Data availability - Key to Trustless Blockchains
Data Availability Layer


Need for Spee Data Availability
In the early days of blockchain, each node that was running the Bitcoin network downloaded and stored the entire blockchain and also processed the transactions. With increased demand from applications, scaling solutions were required, which led to solutions like rollups, and lite nodes that did not download the entire data, but depended on the full nodes. This has created a need to address data availability in this scaling landscape.
INDEX
Why Data Availability Matters?
Data Availability and Rollups
Types of Nodes and How they support the DA Layer
Transaction Flow and Role of DA
Need for a Separate DA Layer
On-chain and Off-chain DAs
EIP 4844 and Dank Transactions?
Off-chain and Hybrid DAs
DA Designs - EigenLayer, Celestia, Avail & Espresso
Conclusion
Why Data Availability Matters?
Consensus mechanisms and data availability are the two factors that contribute to the blockchain's value proposition as a trustless computing system.
The consensus mechanisms ensure that the participants in the network agree on the order and validity of transactions. This makes it possible to collectively reach the system's state without any centralized intermediary. The consensus is reached based on the information in each block that precedes and is related to each transaction. So to reach a consensus, all the nodes of the blockchain must have access to the same data. This is the purpose of a DA layer. It ensures all the data required for each node to independently verify the transaction is available.
Data Availability and Rollups
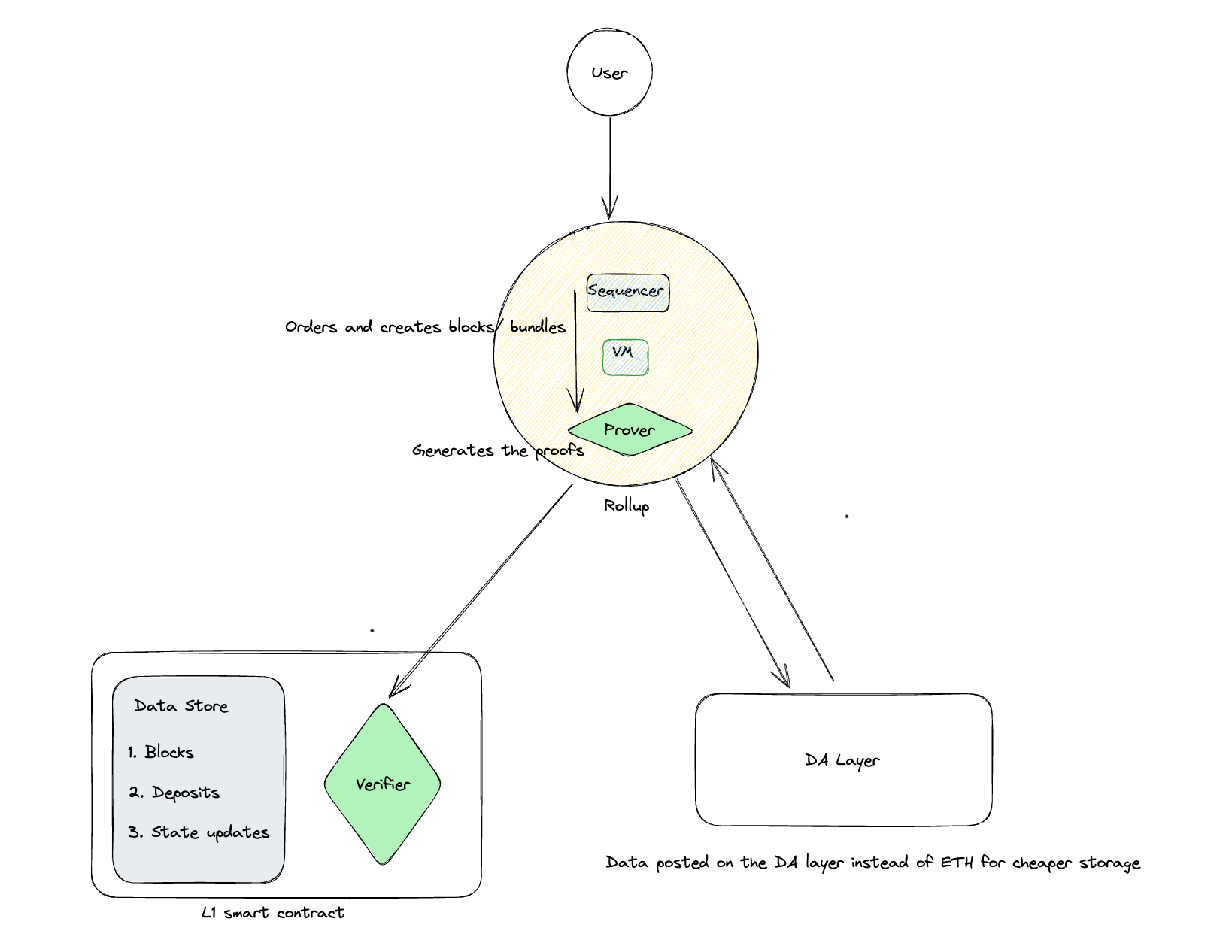
Rollups process and batch transactions off-chain, but these transactions are not considered final without the settlement on the L1. Rollups post proofs for batches on the DA layer so that they can be verified and then finalized. In this way, the DA layer acts as a critical link between the off-chain execution environment and the settlement on the main Layer 1 blockchain. Without a robust DA layer, the integrity and trustworthiness of rollup executions would be compromised. Here’s how the DA layer interacts with different kinds of rollups.
Optimistic Rollups
Optimistic rollups post compressed transaction data to Ethereum and wait for some time (typically 7 days) to allow independent verifiers to check the data. If anyone identifies a problem, they can generate a fraud-proof and use it to challenge the rollup. This would cause the chain to roll back and omit the invalid block. This is only possible if data is available. Currently, data is made permanently available as CALLDATA, which lives permanently on-chain.
However, EIP-4844 will soon allow rollups to post their transaction data to cheaper blob storage instead. This is not permanent storage. Independent verifiers will have to query the blobs and raise their challenges within ~1-3 months before the data is deleted from Ethereum layer-1. Data availability is only guaranteed by the Ethereum protocol for that short, fixed window.
ZK Rollups
Zero-knowledge (ZK) rollups don't need to post transaction data since zero-knowledge validity proofs guarantee the correctness of state transitions. However, data availability is still an issue because we can't guarantee the functionality of the ZK-rollup (or interact with it) without access to its state data. For example, users cannot know their balances if an operator withholds details about the rollup’s state. Also, they cannot perform state updates using information contained in a newly added block.
Full nodes are the main entities that run the blockchain software and ensure DA. Having lite nodes is another way of scaling apart from rollups. Lite nodes are less computationally intensive and allow for more diverse participation in the network, increasing decentralization.
Types of Nodes and How they support the DA Layer
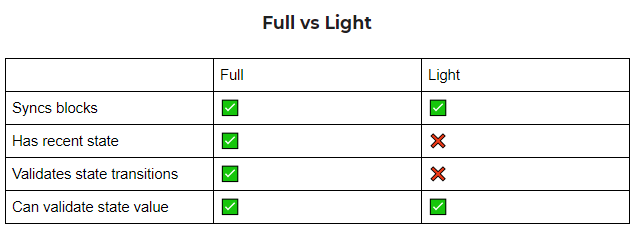
Nodes are basically the computers that run the blockchain software, and in a POS blockchain, they stake their assets and receive rewards for their contributions. There are 2 kinds of nodes, Full nodes and Lite nodes.

Full nodes can download the block header and the data. It requires significant resources to run full nodes. Now, let's talk about rollups. Full nodes play a crucial role here too. They download and verify the transactions happening in rollups and make sure everything is settled correctly. Having full nodes in the mix adds an extra layer of trust. We don't have to rely solely on the rollups themselves for honest functioning.
Lite nodes only have access to the block headers and some transactions. They rely on neighboring full nodes as intermediaries to request needed information, such as downloading block headers, or verifying account balances
Even if they cannot verify the whole block and its transactions, the lite nodes assist in verifying the availability of data using erasure coding. Erasure coding is also the same technology that makes data on a scratched CD still accessible. Let’s see how its done,
Erasure coding, what is it
Instead of relying on a single copy of the data, it is divided into multiple fragments, and additional redundant fragments are generated. These fragments are then distributed across a larger number of nodes within the network. If some nodes become unavailable or lose their fragments, the remaining nodes can still reconstruct the original data by using the redundant fragments.
Lite nodes download a subset of data that is erasure coded, meaning divided after the addition of redundant data. After repeated verification by different lite nodes, the probability that the full data is available can be significantly improved. Hence, even if the lite nodes cannot verify the entire block, they guarantee the availability of data for the full nodes, reducing the burden.
Now that we understand about DA, its relation to rollups, and the main entities carrying out the work of making the data available and verifying the transactions, let's look at how a typical transaction moves through different stages and where data availability enters the picture.
Transaction Flow and Role of DA
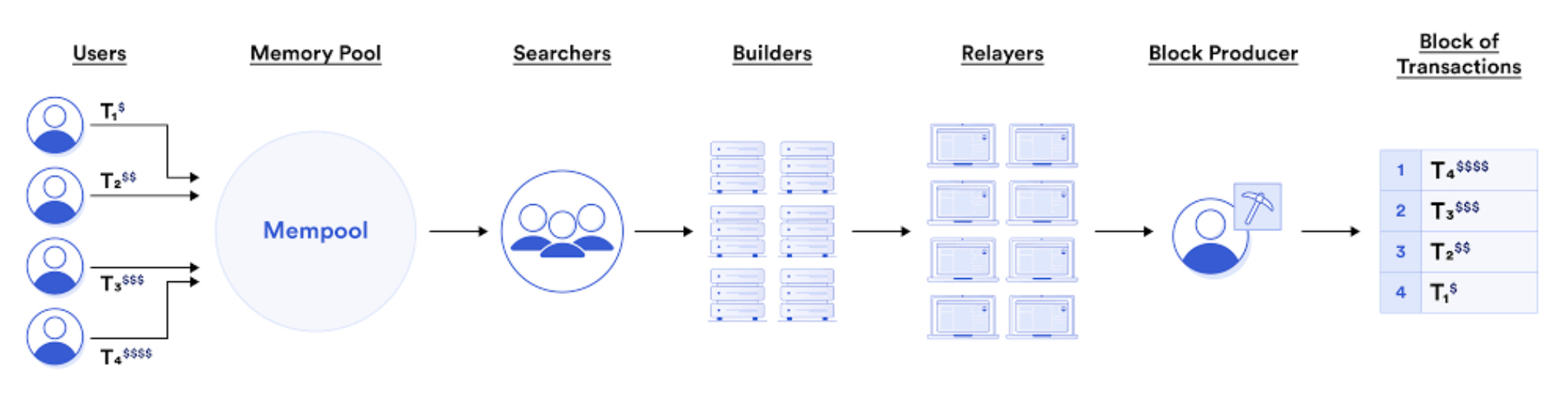
When a user submits a transaction, it is forwarded to the mempool, where it is picked up by searchers (since PBS implementation)
The searcher is responsible for finding txns that meet the network's consensus rules, and checking if the txns have a valid signature, gas price, and priority. In addition, the searcher also makes sure that the data referenced by the txn is available on the blockchain, if it is not available, the txn is not added to the block.
Searchers forward the txns that meet the requirements to the bundlers, who build a block.
Proposers select blocks that lead to the maximum MEV, which are gossiped among the other validators.
Need for a Separate DA Layer
As we have seen, increased demand and bottlenecks led to the creation of modular architecture, where each component focuses on a different role. Rollups rook over the execution off-chain. But still, the amount of data that a blockchain has to make available is on the rise. This is also one of the main components of the cost of transactions on a rollup.
We could scale the DA layer by increasing the block size. But that would lead to increased demands on the node infrastructure, which would make it unfeasible for the small providers. The node provider space might soon get consolidated into entities that have a lot of resources, threatening decentralization. The increased size of the block would also lead to reduced throughput as the full nodes would have to download a larger block each time.
It makes sense to have a separate DA layer that optimizes that function. If the data is stored on a dedicated DA layer,
We get low costs because it may be custom built for the rollup.
Nodes on the main chains, like ETH, can focus on providing consensus security.
Separate DA layers would be easier to update and design for specific use cases. These can be adopted in different configurations by end applications.
DA, like execution, can be done on-chain and off-chain and has its benefits and trade-offs.
Offchain and Onchain DA
EIP 4844 and Dank Transactions?
Danksharding, Proto-danksharding, these names sounds dank, am I right? While the Ethereum Community is pretty dank, these concepts take name after the researchers that proposed EIP 4844, Dankrad Feist and Protolambda. EIP-4844 is all about making Ethereum more scalable. There’s always been a lot of buzz around making Ethereum scalable with Optimistic and Zero-knowledge Proof systems and while they solve for the computation scalability problem, they do not solve the communication complexity problem. While proof systems reduce computational costs at scale by bundling several transactions into a single proof, the transaction data is still large and it needs to be on Ethereum. Think of Ethereum like a big playground where lots of kids want to play, but it's getting crowded. Danksharding comes in to the picture to create more space for the data-hungry parts of Ethereum, i.e rollups.
Now, to make room for these rollups, Danksharding introduces something called "blobs." Imagine these blobs as big storage containers where we can store data. They're huge, but the best part is that they're cheaper to use because they're stored in a special layer that doesn't require much computing power. It's like having a storage unit for your stuff that doesn't cost you much and you can access whenever you need it without having to place the huge container within your own home. With these data blobs, Ethereum doesn't need to know all the details of what's inside them and the EVM does not interpret the blobs. It only needs to know the commitments, like a summary or promise of what's stored in the blob. This makes things much faster and easier for Ethereum to handle. Then there are merged fee markets, which means the cost of using these blobs will be more streamlined and efficient.
Danksharding adds a whopping 16 MB of extra space for rollup data in each block. This is a major development, and we have proto-danksharding to set the stage for it. Proto-danksharding will add only 1 MB of extra space and will also include the verification rules, logic, and gas fee adjustments to prepare for full-on danksharding. Not to say that 1 MB of additional space is insignificant. For context, Rollup blocks carry about 50-100KB of data each, so an additional 1 MB of data availability will bring around greater conveniences of transaction costs and gas fee. This will also allow us to have a glimpse of possibilities of innovation that could arise when full danksharding is in place.
However, there are some things to consider. Blob transactions won't solve all of Ethereum's scalability challenges until they achieve what we call "modularity." It's like when you're building something, and you need to make sure all the different pieces fit together perfectly. Modularity is still a work in progress and comes with its own technical hurdles and delays. Also, as more data is stored on Ethereum, they'll need to clean up or "expire" old data to prevent the playground from becoming cluttered. They can do this by either renting out space off-chain or removing old data on a regular basis and storing it in special nodes. It's like decluttering your room or putting away your toys in a storage unit, so things don't get too messy.

There are some other challenges to figure out too. Like how to handle the gossiping (sharing) of these big blob transactions on the Ethereum network. It's like trying to spread the word about something that's much bigger than what we're used to. And they need to make sure Ethereum can handle all this extra data without getting overwhelmed. This is also known as state bloat problem and several L1 networks are trying to take a crack at it.
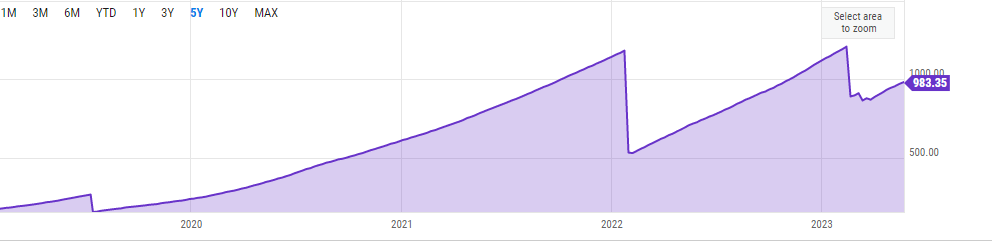
The state is not a history of all transactions but just a snapshot of all transaction and consensus data. Nodes that participate in production and verification of blocks must have the state with them. The state needs constant reads and writes to be updated, thus, increasing its size or “bloat”. As the bloat gets bigger, the reading and writing get slower, leading to other bottlenecks like costlier hardware requirements. The current state size sits at 983 GB.
Off-chain and Hybrid DAs
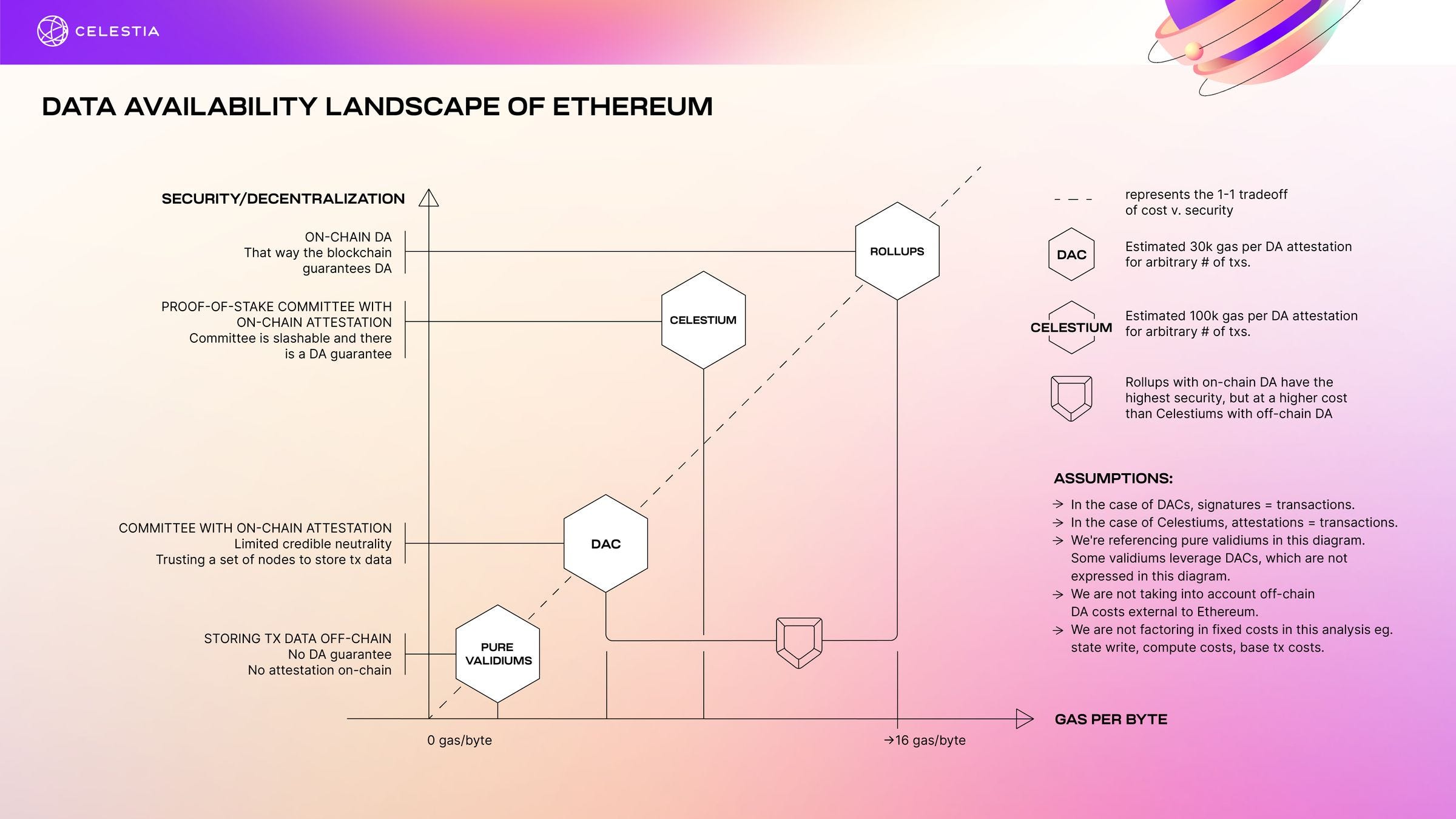
Off-chain data availability (DA) is a scaling technique that moves data storage and computation off the blockchain. This can significantly reduce the load on the blockchain, making it faster and more scalable.
Validiums: Validiums use ZKPs to verify the validity of transactions without storing the data on the blockchain. This makes them the cheapest option for off-chain DA, but it also means that the data availability guarantee is low.
Data Availability Committees (DACs): DACs are a more secure alternative to validiums. Instead of relying on a single data provider, a DAC is a group of trusted nodes that are responsible for storing and making data available to the network. This makes it more difficult for an attacker to take down the chain, but it also increases the cost.
DAC-based Validiums: DAC-based validiums combine the benefits of validiums and DACs. They are cheaper than DACs, but they offer a higher level of security. This is because the data is still stored off-chain, but it is replicated across multiple nodes.
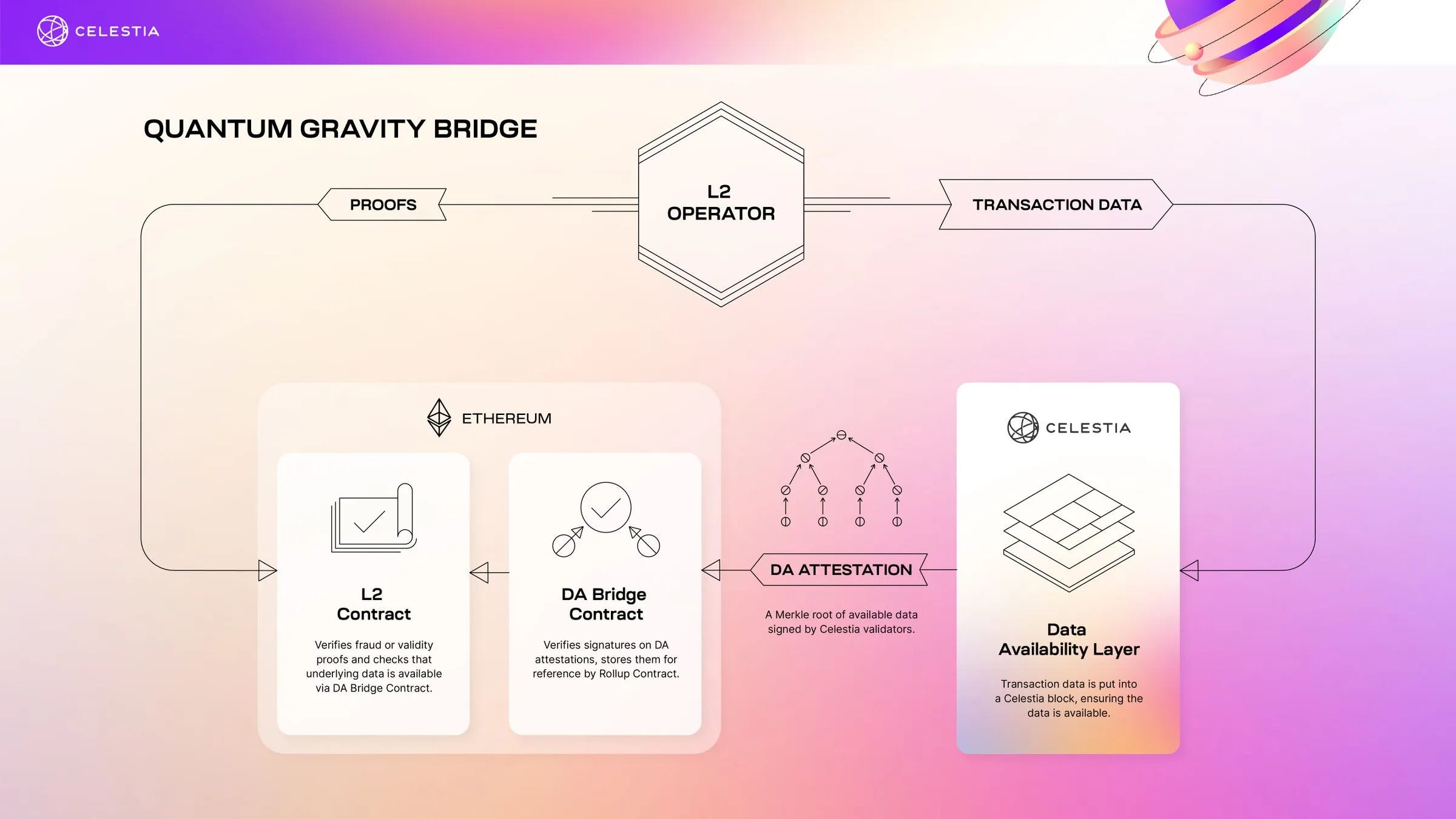
Celestiums are L2 chains that combine Celestia and Ethereum. They leverage Celestia for data availability and Ethereum for settlement and dispute resolution. Celestiums function as permissionless DACs with extra economic guarantees on data availability through possible committee slashing for misbehavior. Light nodes on Celestia can detect unavailable blocks using data availability sampling, automatically halting if the validator set becomes malicious. Celestia, as a general-purpose DA layer, is more credibly neutral than a DAC designed for a specific Ethereum L2.
DA Designs - EligenLayer, Celestia, Avail & Espresso

Several modular DAs have been on the rise, most notably, EigenLayer’s EigenDA, Celestia DA, Polygon’s Avail, Espresso Systems’s Espresso DA and more.
One difference is their block times. Celestia has a block time of 15 seconds, while Ethereum and Avail have block times of around 12 and 20 seconds respectively. Although the differences may not seem significant, they can impact the transaction throughput of the respective platforms.
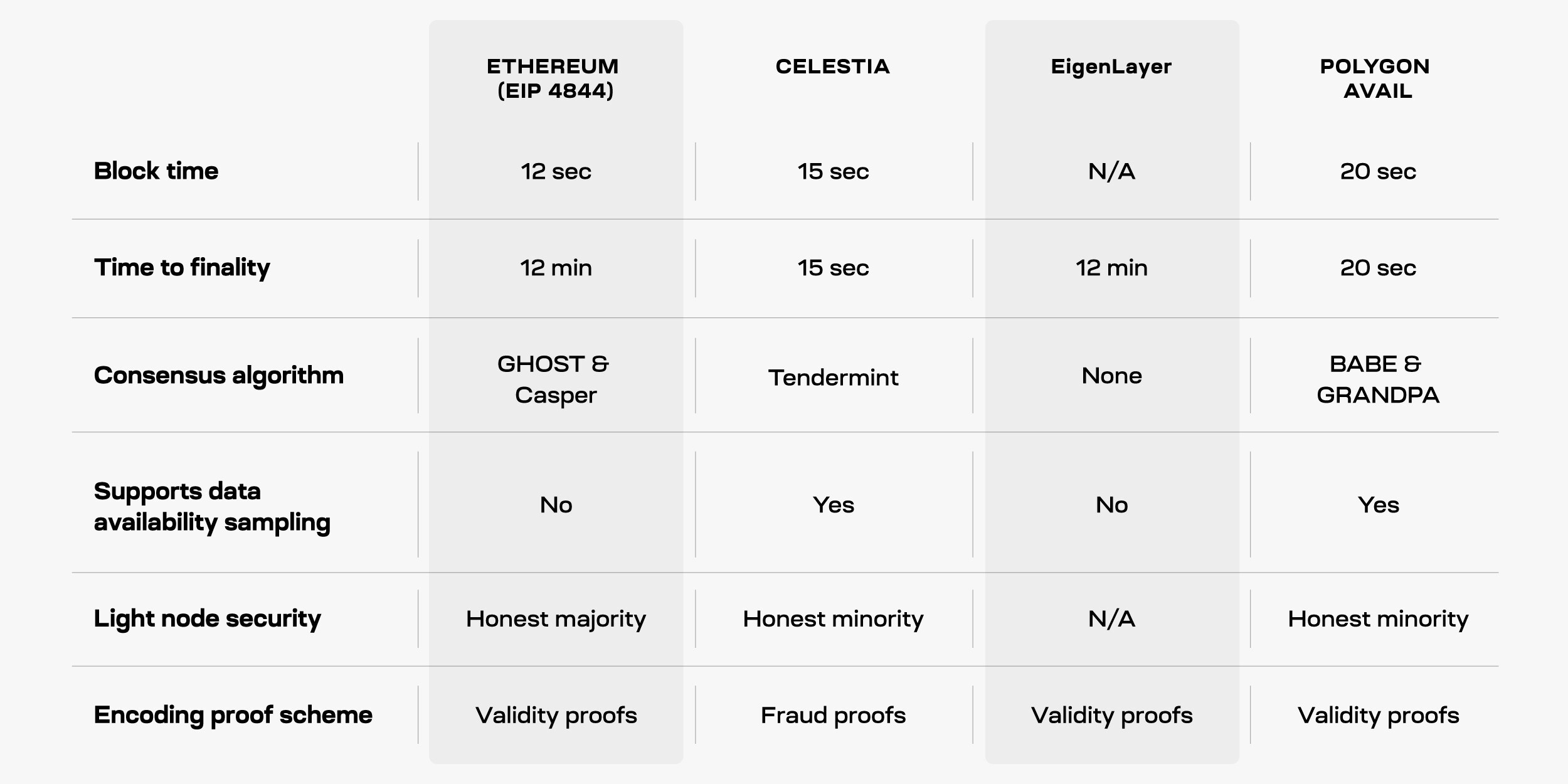
What is more important aspect is the time it takes for blocks to reach finality. Ethereum and EigenLayer have finality times that depend on Ethereum's own finality, which can take around 12-15 minutes. In contrast, Celestia achieves single-slot finality in just 15 seconds, while Avail can take 20 seconds or even multiple blocks to reach finality. These differences in finality times affect how quickly transactions can be confirmed and considered secure within the rollup.
When it comes to Data Availability, Celestia and Avail support data availability sampling, which allows lighter nodes to verify block data without downloading all of it. This approach helps scale data availability without increasing the requirements for nodes. However, Ethereum currently lacks data availability sampling, meaning users need to run full nodes and download all the data for verification. Espresso DA is designed to use VIDs as a fallback if its DAC fails to make data available. As for EigenDA, instead of DAS, it leverages Ethereum’s validator set and It allows Ethereum to offload its DA within the ecosystem security instead of off-chain options. Without DAS, EigenDA offers weaker security than Celestia or Danksharding.
When it comes to security for lighter nodes, Celestia and Avail have implemented trust-minimized security. This means their light nodes can detect invalid blocks. In contrast, Ethereum's light clients lack trust-minimized security and rely on an assumption of an honest majority. This distinction affects the level of security provided by the light nodes in these projects.
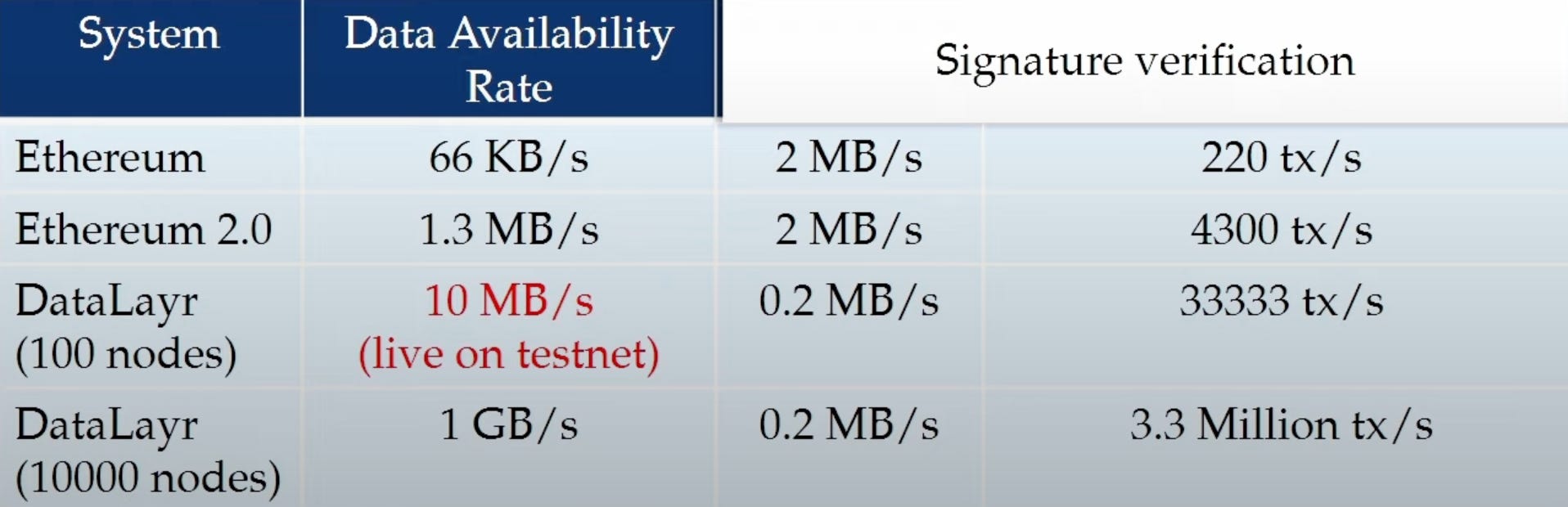
When it comes to consensus mechanisms, Ethereum uses GHOST & Casper, Celestia with Tendermint and Avail have their own consensus algorithms, whereas Eigenlayer is a set of smart contracts on Ethereum, hence, EigenDA inherits the same consensus mechanism. As it does not handle consensus, it also has a much higher throughput than Celestia (1.4MB/s) .EigenDA will achieve up to 15MB/s, which is 176 times more than the DA rate of Ethereum without danksharding. Espresso DA makes use of Hotshot consensus mechanism which prioritizes high throughput and fast finality while complementing Ethereum's consensus model because Ethereum is availability-favoring, and thus does not offer instant finality on transactions.
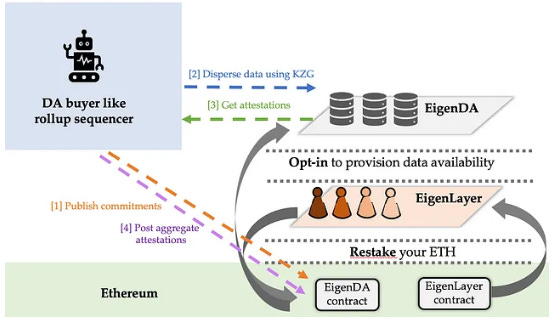
Ethereum, EigenDA, and Avail utilize an encoding-proof scheme similar to ZKRs, to ensure accurate block encoding. Validators produce commitments to the data using KZG proofs, verifying the correctness of the encoding. However, generating commitments for KZG proofs becomes computationally intensive as block sizes increase. Celestia stands out by employing a fraud-proof scheme used by OPRs to identify incorrectly encoded blocks, eliminating the need for costly commitment generation.
Conclusions
Rollup costs are primarily made up of DA costs. A reduction in DA costs for rollups leads to 90% cheaper transactions on a rollup.
ETH, with EIP 4844, has a cheaper DA layer on its roadmap and is a competitor to the alternative DA layers.
DA providers like Celestia have network effects with rollups and rollapps as service providers in the Cosmos ecosystem. Rollups as a service and Rollup SDKs would serve the end applications with easier deployment and customized architecture. These would prove crucial for the DA providers’ GTM.
EIP 4844 proposes danksharding with blob transactions to enhance Ethereum's scalability. While offering benefits for rollup-based solutions, the full implementation and modularity require further development. Challenges such as gas pricing, gossiping, and state bloat need to be addressed, possibly through state expiry mechanisms.
EigenDA leverages Eigenlayer to provide security from the ETH validators. This provides the benefits of ETH's security and the scalability of a separate DA layer. Avail has an entire ecosystem of ZK rollups and dapps on top of it. Building infrastructure after securing distribution on the application layers is proving to be a great strategy.
The low-hanging benefits of being a modular DA layer will not cut it. Eigenlayer or Celestia may not be known as hotshot DA layers (sorry Espresso) a few years down the line if they do solve other inefficiencies. On the other hand, it is yet to be seen as convenient how would Espresso’s approach of providing a sequencer and DA layer for modular systems will be.